After getting an extension on my thesis last week, I've been able to get back into FFTW a bit more, so I started going after the main thing on my agenda; adding non-portable, architecture-specific, neon-enabled fft routines that do NOT use codelets (gitorious). I decided to add these routines in dft/simd/nonportable for lack of a better destination.
The first step was to determine how to expose a new fft algorithm / implementation to fftw's planner. Taking a look at an example like dft/bluestein.c, it was clear that each algorithm / implementation would use a function of the form X(dft_NAME_register) to register with the planner, and that each of the functions to register would need to appear in a const solvtab structure. In dft/conf.c each of the solver tables (standard & simd) are added to the list of possible solvers via X(dft_conf_standard).
In dft/simd/nonportable, a subdirectory for each architecture (in my case 'arm') should be defined, and added to dft/simd/nonportable/codlist.c (if supported).
If the ESTIMATE flag is passed to the fftw planner, then the chosen algorithm / implementation will be based on the number of additions, multiplications, and other operations as reported by all available algorithms and implementations. If the PATIENT flag is passed to the planner, then most available algorithms and implementations will be timed (now I definitely need to fix the armv7a timer code), and the one with the shortest time will be selected. I don't yet know of a way to specifically select which algorithm to use via the advanced or guru interfaces although that useful feature might deliberately not even be available in fftw.
So, now that I have the groundwork laid out, I can go ahead and splice some of the ffmpeg power-of-two fft code into fftw in dft/simd/nonportable/arm. I'll try to get that done within the next day or two. All that's necessary is a bit of a bridge to join the two apis. After that I will begin the interesting journey to see if I can improve the various non-power-of-two algorithms with some elegently crafted assembler code.
Tuesday, July 27, 2010
Monday, July 19, 2010
FFTW: Weekly Report #9
Hi everyone,
There was not a lot of activity this week, mainly due to playing catch-up on my thesis.
Highlights: Misc Repository
- ffmpeg's fft was seperated out of ffmpeg into its own small library (<39kB)
- ffmpeg's fft is integrated with benchfft, for easy visualization
Todos:
* fix real / reverse portions of ffmpeg's benchmark in benchfft
* fix benchfft's graphing features to display runtime rather than mflops on the y-axis.
Please see my last post for an initial graph of ffmpeg's fft vs fftw with neon, as well as details about my plans with fftw.
Thursday, July 15, 2010
This One's For You, Mru
As a follow up to my last post, I thought that I would show everyone a pretty graph with FFMpeg's FFT performance benched against FFTW for powers of two. I think it's obvious who the clear winner is from the image below.

Just for clarification purposes, 'fftw3' means 'fftw without neon simd optimizations', 'fftw3n' means 'fftw with inline asm neon simd optimizations', and 'fftwni' means 'fftw with gcc intrinsic neon simd optimizations'.
All versions of FFTW were compiled with CFLAGS="-O3 -pipe -mcpu=cortex-a8 -mfloat-abi=softfp -mfpu=neon -fno-tree-vectorize". You can get the source at gitorious.org/gsoc2010-fftw-neon.
Now, a few comments.
First of all, NEON intrinsics perform almost identically to inline asm in the 'codelet' department, which really just goes to show exactly what one can expect from GCC's NEON optimization process (i.e. it is not optimized).
Secondly, well optimized assembler will almost always outperform what the compiler is capable of (arguably even when there is a hardware optimizer, see OoOE). The NEON coprocessor does not have an OoOE execution unit (although Cortex-A9 has one for the multiple ARM cores), which means that optimization with NEON is entirely up to the compiler and the programmer.
Lastly, FFMpeg's implementation is only for powers of two (even with very large radices), which means that the way non-power-of-two transforms would be computed with FFMpeg, would be to first be zero-pad the input. Zero-padding is also possible with FFTW, but it must be done before making the call to fftw*_plan. In other words, FFTW does not explicitly zero-pad data (as far as I'm aware, but I could be wrong). From what I understand (based on some random memory fragment suggesting that I read this somewhere a long time ago), programs such as Matlab actually do zero-pad all data before passing it to the FFTW library.
So, for the purists out there, or those who use embedded devices with (really!) small amounts of RAM, this is where FFTW becomes very attractive. FFTW uses several well published algorithms specifically for non-power-of-two problems to efficiently compute transforms without zero-padding. An alternate interpretation is that it's better for large input signal lengths (in the order of 2^27+1), if one were that naive, since the next power-of-two could max out available RAM. That's up for some debate anyway, and I don't know very many people who would do that on an ARM device (thankfully).
Now, the next plan is to determine how to augment the existing plans that FFTW has, to use similarly optimized power-of-two algorithms to those from FFMpeg. Then, the next step would be to tackle some of the non-power-of-two algorithms and try to rewrite them in NEON assembler. According to FFTW, even those non-power-of-two algorithms are O(NlogN), so perhaps (just perhaps), they will show a similar level of performance when written directly with ASM.
In short, I now have a visual depiction of what I should be shooting for. I will keep you posted on how well that goes.
PS: If you're wondering who Mru is, he's indeed my mentor for GSOC and maintainer for ARM portions of FFMpeg.

Just for clarification purposes, 'fftw3' means 'fftw without neon simd optimizations', 'fftw3n' means 'fftw with inline asm neon simd optimizations', and 'fftwni' means 'fftw with gcc intrinsic neon simd optimizations'.
All versions of FFTW were compiled with CFLAGS="-O3 -pipe -mcpu=cortex-a8 -mfloat-abi=softfp -mfpu=neon -fno-tree-vectorize". You can get the source at gitorious.org/gsoc2010-fftw-neon.
Now, a few comments.
First of all, NEON intrinsics perform almost identically to inline asm in the 'codelet' department, which really just goes to show exactly what one can expect from GCC's NEON optimization process (i.e. it is not optimized).
Secondly, well optimized assembler will almost always outperform what the compiler is capable of (arguably even when there is a hardware optimizer, see OoOE). The NEON coprocessor does not have an OoOE execution unit (although Cortex-A9 has one for the multiple ARM cores), which means that optimization with NEON is entirely up to the compiler and the programmer.
Lastly, FFMpeg's implementation is only for powers of two (even with very large radices), which means that the way non-power-of-two transforms would be computed with FFMpeg, would be to first be zero-pad the input. Zero-padding is also possible with FFTW, but it must be done before making the call to fftw*_plan. In other words, FFTW does not explicitly zero-pad data (as far as I'm aware, but I could be wrong). From what I understand (based on some random memory fragment suggesting that I read this somewhere a long time ago), programs such as Matlab actually do zero-pad all data before passing it to the FFTW library.
So, for the purists out there, or those who use embedded devices with (really!) small amounts of RAM, this is where FFTW becomes very attractive. FFTW uses several well published algorithms specifically for non-power-of-two problems to efficiently compute transforms without zero-padding. An alternate interpretation is that it's better for large input signal lengths (in the order of 2^27+1), if one were that naive, since the next power-of-two could max out available RAM. That's up for some debate anyway, and I don't know very many people who would do that on an ARM device (thankfully).
Now, the next plan is to determine how to augment the existing plans that FFTW has, to use similarly optimized power-of-two algorithms to those from FFMpeg. Then, the next step would be to tackle some of the non-power-of-two algorithms and try to rewrite them in NEON assembler. According to FFTW, even those non-power-of-two algorithms are O(NlogN), so perhaps (just perhaps), they will show a similar level of performance when written directly with ASM.
In short, I now have a visual depiction of what I should be shooting for. I will keep you posted on how well that goes.
PS: If you're wondering who Mru is, he's indeed my mentor for GSOC and maintainer for ARM portions of FFMpeg.
Sunday, July 11, 2010
Fftw-Neon: Weekly Report: Week 8
Over the last week, I did some more benchmarking, and also began working ffmpeg_fft into my benchmarks for a good target to aim for. I'm currently working out a segfault in the ffmpeg_fft library (specifically in ff_fft_permute_neon.S) and hope to have a few more pretty graphs to show for next time. I added fftwni to the benchmarks in order to compare codelets coded in inline asm versus codelets coded in neon intrinsics (also started using -O3 for -finline-functions), and the results were very close for fftwn (inline neon asm) and fftwni (inline neon intrinsics). The one exception I made was that vtrn was coded in inline asm to prevent compiler errors revolving around being unable to spill registers. Also, I'm changing the graphs to directly show cycles (or time) instead of mflops. The next major step will be working power-of-two fft 'algorithms' into the fftw planner. After that I'll be tackling the much more interesting non-power-of-two algorithms. By directly coding specific algorithms in asm, we're hoping to achieve a greater speedup than what is possible with codelets. The asm routines do not necessarily need to completely displace the codelets from the point of view of the planner (at least not without hard proof that they are always faster), so they can possibly augment the pool of algorithms available to the planner.
I will need to have some serious crunch time for my thesis as well, since the submission deadline is in 19 days (!), so you might not see as many commits in my repositories this week. Please feel free to look at the latest in main and misc.
I will need to have some serious crunch time for my thesis as well, since the submission deadline is in 19 days (!), so you might not see as many commits in my repositories this week. Please feel free to look at the latest in main and misc.
Tuesday, July 6, 2010
Results from Inline Asm / Codelets
I thought I would post the initial speed results achieved using the latest inline asm patch for neon-simd.h . The results are decent - a 2x mflop improvement in some cases - but I'm still aiming to get approximately a 10x speedup on average, which will require some pretty intensive assembly coding. The results below are ony for powers of two, just for a quick overview. Also, I'm trying to completely eliminate in-place transforms from the benchmark, since fftw always performs simd transforms out-of-place (as far as I can tell), and out-of-place transforms are generally faster anyway.


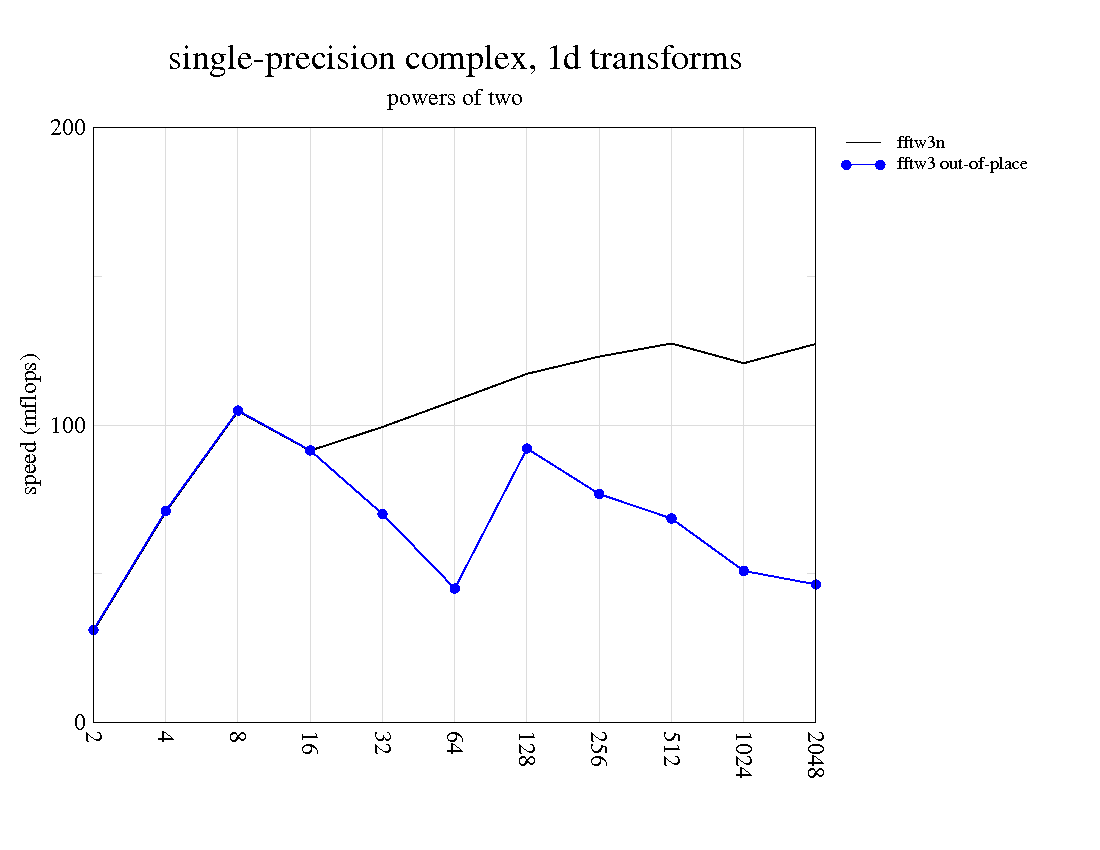

Sunday, July 4, 2010
FFTW: Weekly Report - Week 7
Over the last week, I've spent a fair amount of time implementing the "standard" fftw simd interface for neon using intrinsics, and one thing is certainly clear: there is absolutely no throughput gained at all, as you can see in the graph below. And yes, I was definitely using neon code for fftw3n. These results were more or less expected (although maybe not so exactly), since I was really only using intrinsics for verification purposes, and obviously inline C functions with intrinsics produce some undesirable effects. As far as numerical accuracy goes, its identical to the non-simd version, which is good. The benchmark was made via benchfft for consistency, and you can grab a copy of it from my misc repository.

Below is an example of how the VMUL and VZMUL inline functions appear in the disassembled .so file when using intrinsics. They shouldn't actually appear at all as seperate sections. The best way to eliminate all of those useless branches, push's and pop's, is to rewrite each inline function in simd-neon.h with inline asm statements.

Below is an example of how the VMUL and VZMUL inline functions appear in the disassembled .so file when using intrinsics. They shouldn't actually appear at all as seperate sections. The best way to eliminate all of those useless branches, push's and pop's, is to rewrite each inline function in simd-neon.h with inline asm statements.
000dc268 :
vmul.f32 q0, q0, q1
bx lr
...
...
00149cf0 :
vorr q8, q0, q0
vtrn.32 q0, q8
push {lr} ; (str lr, [sp, #-4]!)
vpush {d8-d13}
sub sp, sp, #68 ; 0x44
vstr d16, [sp, #16]
vstr d17, [sp, #24]
vstmia sp, {d0-d1}
mov lr, sp
add ip, sp, #32 ; 0x20
ldm lr!, {r0, r1, r2, r3}
vorr q6, q1, q1
stmia ip!, {r0, r1, r2, r3}
vldr d0, [sp, #32]
vldr d1, [sp, #40]
ldm lr, {r0, r1, r2, r3}
stm ip, {r0, r1, r2, r3}
vldr d8, [sp, #48]
vldr d9, [sp, #56]
bl 149c30
vorr q5, q0, q0
vorr q0, q6, q6
bl 149c38
vorr q1, q0, q0
vorr q0, q4, q4
bl 149c30
vorr q1, q0, q0
vorr q0, q5, q5
bl 149ce8
add sp, sp, #68 ; 0x44
vpop {d8-d13}
pop {pc}
On a side note, I did discover that some as-of-yet unidentified effect of the armv7 cycle-counter was making my benchmarks hang, so that was currently configured out in my test libraries (--enable-armv7-cycle-counter is not set).
On another side note, all of my simulations seem to indicate that simd transforms are always out-of-place. This is probably a good thing in any case because out-of-place transformations tend to be faster, but it also might allow me to implement pointer/register auto-incrementing (with ldxxx {xx} [rx]!) .
In pure C / neon intrinsics, there is no way to specify load-store alignment (major speedups lost) or pointer auto-increment (more arm instruction syncopation). Ideally, there would only be a few seldom, conditional branches in arm code while most of the work was done in the neon coprocessor.
In case anyone would like to test the library out on their own, I'm configuring fftw3 with
CFLAGS="-Os -pipe -mcpu=cortex-a8 -mfloat-abi=softfp" ./configure --prefix=/usr --host=arm-none-linux-gnueabi --enable-float --with-pic --enable-neon --enable-shared
I would highly suggest adding -mfpu=neon to the cflags above as well (for all code), otherwise configure.ac only adds -mfpu=neon to simd-specific compiles.
Although I did get quite a bit done this week, it's been slower than I would have liked for two reasons: 1) Canada Day (daycare is closed), and 2) my significant other was on the other side of the continent for an academic visit, and so I've been a single parent this week. Although I did get to spend lots of extra time with my son, which is always welcome, i think I lost about 1 or two hours a day getting to the daycare and back.
Plans for next week:
1) rewrite inline functions as inline asm instead of inline with intrinsics
2) speed-ups!
3) continue investigating codelet-free approaches (i.e. sacrificing the fftw methodology for speed)
4) fix cycle counter!
Subscribe to:
Posts (Atom)