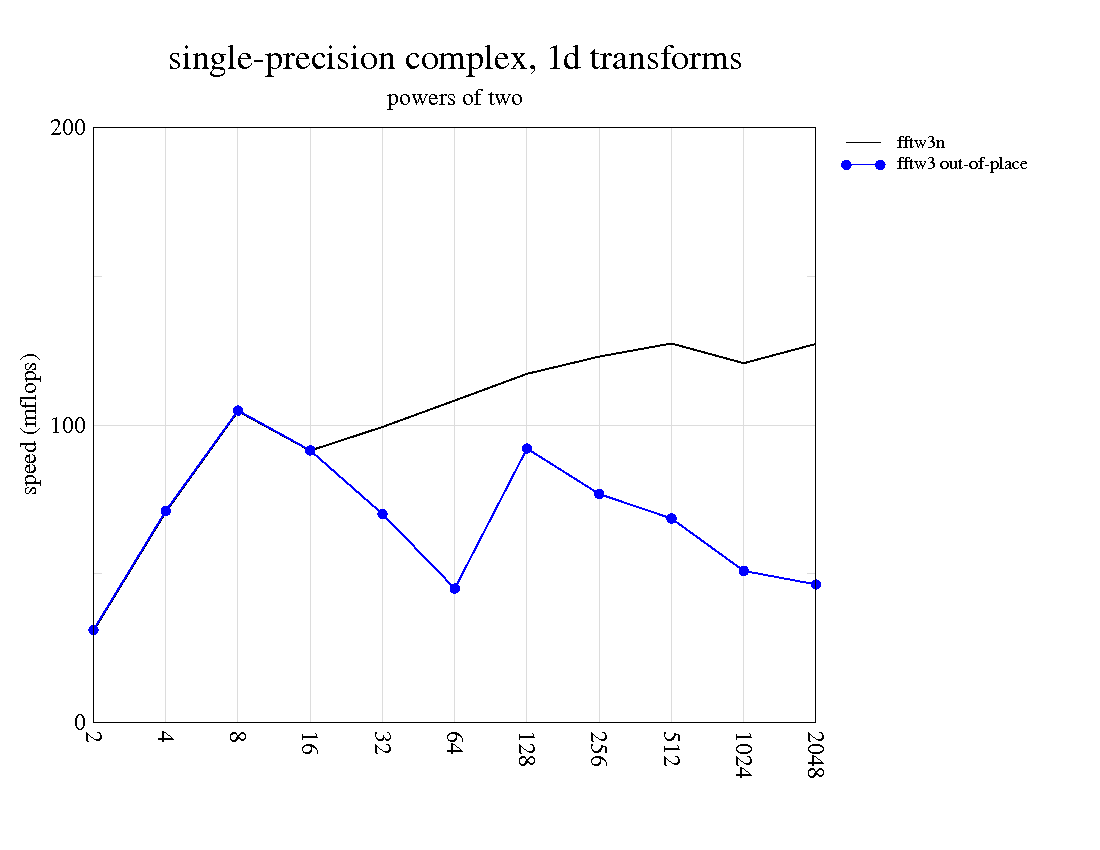
After much anticipation, here are my very-belated weekly updates, along with another few lovely graphs.
update-20100819(am): I had to restart the benchmark before I left for the lab this morning because the ffmpeg can_do() function in my benchfft source caused a double free error in glibc. I fixed it this morning (removed the out-of-place junk). The benchmarks will be ready by when I get home. Since these are my final benchmarks, I'll copy / paste the timing data into oocalc and finally make time on the y-axis instead of mflops. It's a bit of a pain that benchmarking takes 4-6 hours. Sorry for the delay.
update-20100818: Arg! A bug-ridden, cycle-hungry udevd process was absolutely killing the metrics of my last benchmark. It happens every time I reboot, and I just haven't gotten around to fixing it yet. Usually I remember to kill udevd before doing anything else but I must have accidentally cycled the power on my Beagle last night before starting the benchmark. Below is one graph from the results (which I will replace as soon as the next set of results is finished). You can see several more results of
neon performance under heavy load (and its still pretty decent!). Particularly, it's an interesting experience to see how neon just jogs leisurely along while 'top' shows a single process using 95% of the cpu cycles. If you look at the graphs under heavy load, you'll probably also notice how strided and non-strided meory transfers take a beating. I've already restarted the benchmark and should have some new graphs up later tonight.
When I set out to improve
FFTW on
NEON-enabled ARM processors, the main goal and focus was to be on the
TI OMAP 3430, for the
BeagleBoard Project and that I did. Originally, the speed increase was rather modest (1.5-2x or so), because I simply implemented the SIMD / codelet API that most architectures use already. However, the NEON coprocessor has no hardware instruction rescheduling (i.e. it is in-order), nor does the Cortex-A8 core, and without those two things (not to mention better scheduling from GCC), FFTW's codelet interface does not perform nearly as well as hand-written assembly code. In contrast, on
x86 processors, the benefit of the OOE unit (and likely far better compiler optimizations) is clearly visible, as FFTW outperforms FFMPEG even on my eee701 (shown in the graphs
below). The Cortex-A9 does have an out-of-order unit, but its unlikely that this will have a major impact on NEON scheduling.
My
most recent BeagleBoard performance comparison included
FFMPEG's transform for powers of two, which was faster by far than FFTW using codelets, so I knew that I had some high goals to reach. I originally thought it would be smart to transpose lots of highly optimized assembly into a new non-portable / architecture dependent simd sub folder in FFTW, trying my damndest to get my code to measure up to FFMPEG, but then I realized that was just stupid when there was already a perfectly optimized FFMPEG library right in front of me. Next, I went to lots of extra trouble to create a seperate ffmpeg_fft library which I bundled with FFTW. That was fine, although I did dig up an interesting alignment related bug with respect to how FFTW handles FFTW_FORWARD and FFTW_BACKWARD. Also, I think I may have also dug up another cortex-a8 errata-worthy tidbit, or have found a bug in the Linux kernel's handling of neon instructions... but that's slightly tangential.
Since my last post, I've smoothed over my work, added the beginnings of NEON copy acceleration for buffered / rank-0 transforms, and ran a few tests that you can check-out
here (
here) and
here. The results might be surprising even for the non-power-of-two cases. I was surprised at first, myself. Originally, I was curious as to how many of the non-power-of-two / prime algorithms worked. After some perusal of related articles on
IEEEXplore, I learned that many of the non-power-of-two algorithms (i.e.
Bluestein,
Rader) rely on some form of recursion or composite solution where power-of-two DFT's (or other small, prime factors) are often key, which why non-power-of-two performance was slightly increased with NEON SIMD codelets and FFMPEG routines. In the non-power-of-two case, typically what would happen is that . I found Rader's algorithm to be particularly interesting; these days its treated as common knowledge in most advanced DSP courses. Non-power-of-two routines are still not as fast as ffmpeg's power-of-two algorithms, but it might be possible to improve that with a bit more work on NEON copy acceleration.
A few technical details:
- Not only the DFT, but also the RDFT, DCT, and DST interfaces to FFMPEG were brought out into FFTW, which gives much more flexibility for varying applications.
- Currently the FFMPEG interfaces stick with the in-place, contiguous, and aligned API of FFMPEG. That is, any non-aligned, or composite transforms require buffering before feeding them into FFMPEG. In FFTW terms, changing strided data into a non-strided data is called a rank-0 transform. Rank-0 transforms always occur for composite DFTs, and thus, require a very efficient set of copying routines.
- The ARMv7 cycle timer made a major difference to performance, since simple estimation methods were not being used to choose an algorithm. I would highly suggest that people apply Mans' USER_PMON patch and recompile their kenel before trying out my changes.
- Since FFTW's interface to FFMPEG is generic, the native library may or may not actually use native SIMD instructions. As we all know, misalignment with SIMD instructions are bad, so it's necessary to ensure that input data is properly aligned. Currently FFMPEG uses a constant 16-byte alignment, which is straight forward to account for, but FFTW does a clever little swap of real and imaginary input pointers to indicate an IDFT (i.e. data is no longer aligned). After some time, I found a bit of trickery to get around that, which I will document further on elinux.org.
- Lastly, if you choose to link with FFMPEG, please ensure that you have --enable-hardcoded-tables selected. Otherwise, FFMPEG (current git) will cause a segmentation fault (in cos table initialization). That is an FFMPEG related bug that I was unlucky enough to encounter during my testing phase.
Having a cycle counter means that FFTW will no longer be restricted to running in ESTIMATE mode on ARMv7, which will allow it to accurately time several different strategies, and then store wisdom files to speed-up future calculations.
So the bottom line, is that FFMPEG's blazingly fast power-of-two transforms are a benefit to all of FFTW's algorithms including those for prime and non-power-of-two input length. However, such composite transforms rely heavily on efficient strided memory copy algorithms (rank-0 transforms). Since I only just started chipping away at that (for NEON), the performance for non-power-of-two transforms is still less than ideal. Also, I should note, that any higher-order transform (e.g. for images or volumes) also requires highly efficient rank-0 transforms. Hence, none of my graphs are showing higher-order throughput results.
There is one more thing worth noting. Rather than using a bundled ffmpeg_fft library inside FFTW (as I initially did for testing), I decided to take the simple and obvious approach. That is, I chose to link to FFMPEG from within the FFTW code dynamically (statically linking is also possible). Why?
- maintenance becomes much easier,
- bundled libraries are inherently evil, and
- my contribution then becomes architecture agnostic.
Rather than solely benefiting NEON-enabled processors, it actually benefits all architectures that have support in both FFTW and FFMPEG. The list includes all x86 variants, some PowerPC variants, the dozens ARM SoC's with a NEON coprocessor (e.g. OMAP, i.MX, and handfuls of others), and likely more. It's like killing 100 birds with a single stone ;-) Please note, that there are some non-power-of-two cases, as shown in the graphs, where my code in simd-neon.h (fftwfn) actually outperforms the mish-mash of power-of-two composites that the fftwff (ffmpeg) version generates. So it's nice to know that it is, on occasion, useful. Once NEON copy acceleration is finished, it will likely also have a major improvement.
In the most ideal case,
genfft would have been optimized to directly output optimized ARM / NEON machine code, much like a
JIT compiler, but that would probably take much more time than was available. At this point, I think I can finally say that I'm happy with FFTW's throughput results (and the potential for improvement with acclerated NEON rank-0 transforms) even through the 'brute force' methods that I chose. That being said, although the code is more-or-less finished and more-or-less bug-free, the fftw-neon project still. I will probably only have time to do some instructional documentation, and a demonstration screencast, but it shouldn't be too hard to put together a bitbake recipe at a later date.
Although I thoroughly enjoyed working on this project and did put a lot of time into it (some of which really should have been dedicated to my MSc thesis), much of the credit should be attributed to the authors of FFMPEG and FFTW. I also would like to thank the people who offered me advice and encouragement - specifically my mentor Mans, Matteo from the FFTW project, as well as Jason and Koen from #beagle. It has definitely been a good experience working on FFTW, and I feel inclined to do some further optimizations on it in the future. Specifically, that would include NEON-accelerated rank-0 transforms and perhaps some small-prime algorithms in NEON assembler (e.g. for N=3, 5, 7).
Please drop me a line if you find this work useful - I always love to hear how I've helped others out. Also, within the next few days, please feel free to visit
my project page on
elinux.org for documentation, instructions, demonstrations, and more. In case anyone is interested, you could probably also anticipate seeing the results of this project ending up in a certain free version of a popular
MAtrix ma
Th
Libr
Ary,
Built for mobile devices (i.e. GNU Octave).